Drawing random biscuits: from probability to data
I stumbled upon a probability exercise when I had just built enough confidence with R scripting, and I was looking for “toy problems” to play with. It was a simple brain teaser, barely more complicated than the well-known coin toss. I could solve it with pen and paper, but I wanted to squeeze out of it as much as I could.
My central thesis in this post is that, if we formulate our assumptions well, we can turn questions about probability into questions about data.
The problem
You have three biscuits in a box. Each biscuit has two sides, and each side is covered in either white icing or chocolate. One biscuit has two chocolate sides. The second biscuit has one chocolate and one white icing side. The third biscuit has two white icing sides.
You reach into the box, draw out a biscuit and place it flat on the table. A chocolate side is shown facing up, but you do not know the color of the side facing down. Prove that the probability that the other side is also chocolate is
\(\frac{2}{3}\).
Let’s take it apart. The problem asks a question based on certain assumptions. These assumptions are what I’m going to call a system and a process.
The system
There are 3 biscuits in the box:
-
Both sides covered in chocolate
-
One side covered in chocolate and one covered in icing
-
Both sides covered in icing
The process
One random biscuit is drawn out. We see that its up-facing side is covered in chocolate, but we don’t see its down-facing side.
The task
Show that the probability of its down-facing side being also covered in chocolate is \(\frac{2}{3}\) (or 0.666…).
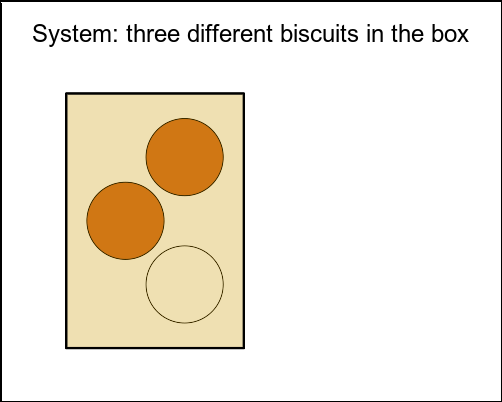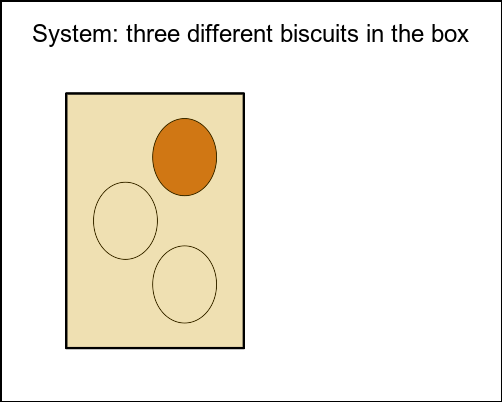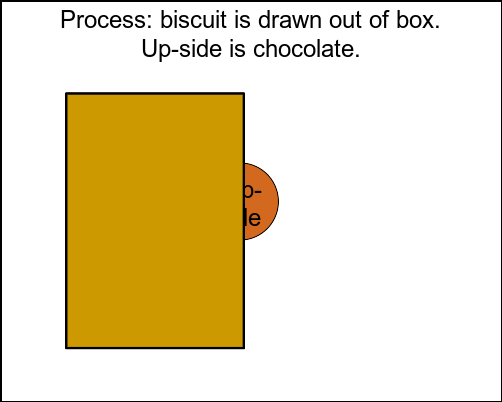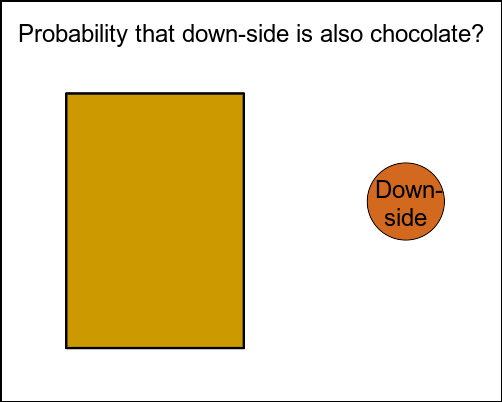
Figure 1: Biscuit-drawing problem
How not to solve it
If we feel really confident, we can go along this line of thought:
-
The up-facing side of our drawn biscuit is covered in chocolate, so there are two possibilities:
-
Either it is the one whose both sides are covered in chocolate
\(\implies\)its down-facing side also has chocolate, -
or it is the mixed one
\(\implies\)its down-facing side has icing.
-
-
This means that the probability of the down-facing side being chocolate is 50%, or
\(\frac{1}{2}\).
And we already know we’re wrong, because our result is not \(\frac{2}{3}\).
So… what went wrong? Well, it all started when we felt really confident and “solved” it in a matter of seconds. Because of this, we didn’t formulate the assumptions correctly.
The correct pen-and-paper way to solve it is shown at the end of this post, but for now, let’s see how we can make the computer solve it for us.
Solution
The task concerns probability, which is about predicting future outcomes. Now, computers are not very good fortune-tellers but they are good at processing data.
To take advantage of this, we can turn the task into a statistical one:
“Show that 2 out of 3 (
\(\frac{2}{3}\)) times that a chocolate side was placed facing up, the side facing down was also chocolate.”
This is not a question about probability of outcomes anymore, it’s about frequency of events.
Simulate and collect data
All code used for this post is in the R programming language.
First, we define the system: 3 biscuits and the box containing them.
# Biscuits with 2 sides are defined (vectors with 2 elements)
biscuit.1 <- c("chocolate","chocolate")
biscuit.2 <- c("chocolate","icing")
biscuit.3 <- c("icing","icing")
# and are placed in a list named "box"
box <- list(biscuit.1,biscuit.2,biscuit.3)
Code explanation
-
Each biscuit is defined as a vector of type
characterand assigned to a variable with the<-operator (see assignment to a variable for more details). -
The 3 biscuits are placed in a list, which is similarly assigned to a variable named
box.
Next, we simulate the process of biscuit drawing repeatedly, and collect the data. Any large number of repetitions will do. The code below performs this 2000 times and collects the results in a data.table named biscuit.draws for further analysis.
I use the data.table package for filtering and summarizing data (to experienced R users: no disrespect to the Tidyverse, I just avoid it as much as I can).
# How many biscuit draws to simulate
total.draws <- 2000
set.seed(seed=1)
# Load the data.table library
library(data.table)
biscuit.draws <- lapply(
X=seq_len(total.draws),
FUN=function(i,box) {
# The following steps simulate each biscuit draw from the box:
draw <- box |>
# 1. Draw one random biscuit
sample(size=1) |> unlist() |>
# 2. Place it randomly on one side, like a coin flip
sample(size=2)
# Return the result of a random draw and placement as a list
return(
list(up.side=draw[1],
down.side=draw[2]))
}, box=box) |> rbindlist()
Code explanation
The set.seed function initializes conditions for the following random process, ensuring reproducible results. See details on initializing seed.
After total.draws is set to 2000, the lapply function iterates a random biscuit draw 2000 times (see details on applying a function over a vector or list). The 2000 results are returned as a list and then stacked on top of each other in a data table, using rbindlist.
-
X=seq_len(total.draws)specifies each iteration with a sequence from 1 tototal.draws(see sequences for more details). -
FUN=function(i,box)is a custom function, performing the actual biscuit draw and placement within curly brackets ({ }). Thedrawvariable is assigned the result of the following piped processing steps (see details on piped function calls):-
sample(size=1)randomly draws one element from theboxlist (see random samples for more details). Thesamplefunction creates a list of one element, so weunlistit to just keep the individual element - one of the biscuit vectors. -
sample(size=2,replace=FALSE)simulates a random placement of the drawn biscuit, just like a coin toss (see details on simulating a coin toss).
The result of each draw is returned as a list, so the end result of
lapplyis a list of lists. We do this because it is compatible with the followingrbindlistoperation. -
Arguments to FUN:
-
i: Changes in each iteration, taking the values ofX(from 1 to 2000). -
box: The list of 3 biscuits we previously created. It is passed inside the function after its curly brackets and remains the same throughout all iterations.
Results
Let’s take a quick peek at our data:
biscuit.draws
## up.side down.side
## <char> <char>
## 1: chocolate chocolate
## 2: chocolate chocolate
## 3: icing icing
## 4: chocolate icing
## 5: chocolate chocolate
## ---
## 1996: chocolate chocolate
## 1997: chocolate chocolate
## 1998: chocolate chocolate
## 1999: chocolate chocolate
## 2000: icing chocolate
Indeed, there are 2000 rows, and each row shows the results of one drawing process. Let’s count how many times each different type of side was placed facing up:
biscuit.draws[,.(count=.N),by=up.side]
## up.side count
## <char> <int>
## 1: chocolate 1013
## 2: icing 987
Code explanation
This code displays an aggregate table, grouping the rows by their up.side - in other words, grouping the biscuit draws by the resulting up-facing side.
.N is a special symbol in data.table, giving the number of rows. Therefore, this piece of code shows how many biscuit draws resulted in each type of up-facing side.
Chocolate and icing were drawn as up-facing sides about half of the times each (1013 and 987, out of 2000 total draws). Now let’s count how many times each combination of sides was drawn:
biscuit.draws[,.(count=.N),by=.(up.side,down.side)]
## up.side down.side count
## <char> <char> <int>
## 1: chocolate chocolate 667
## 2: icing icing 656
## 3: chocolate icing 346
## 4: icing chocolate 331
Code explanation
Similarly, this piece of code groups and counts rows by the value of both up.side and down.side.
So, from the 1013 times the up-facing side was chocolate, the down-facing side was also chocolate 667 times - suspiciously close to \(\frac{2}{3}\) of 1013.
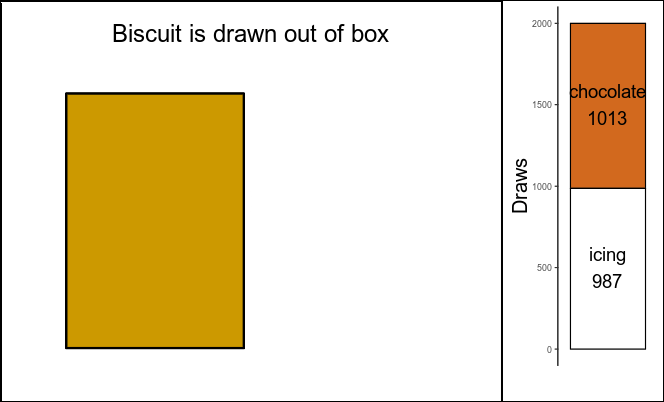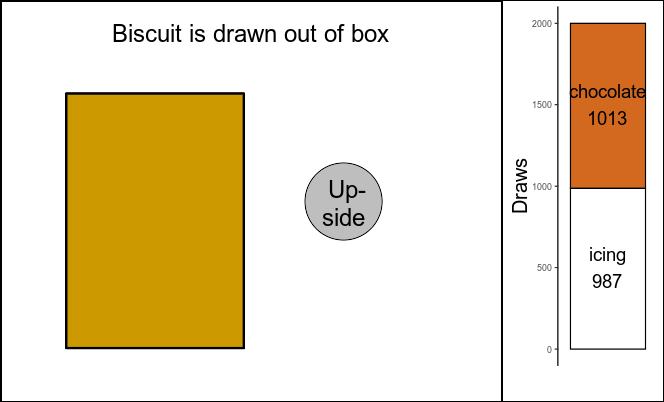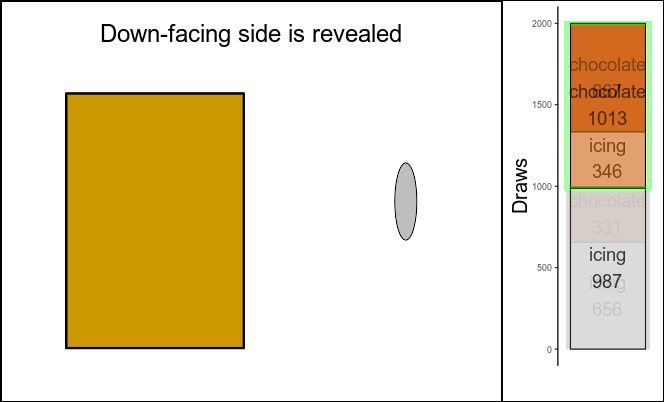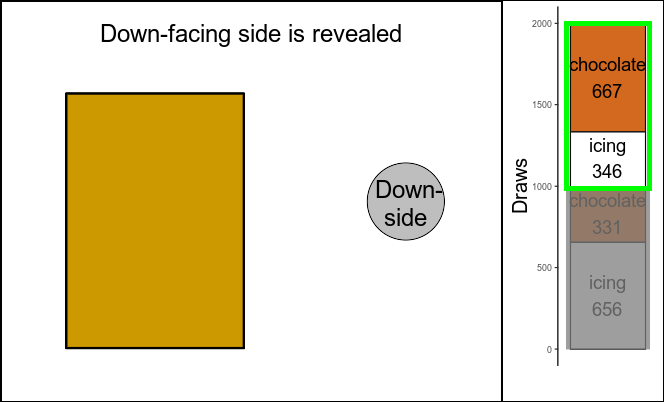
Figure 2: Left: illustration of random biscuit drawing; right: results after 2000 biscuit draws. Green frame on right side: considered cases.
Let’s calculate the exact frequency:
biscuit.draws[up.side=="chocolate",
sum(down.side=="chocolate")/.N]
## [1] 0.6584403
Code explanation
-
To focus on the initial question, we filter the rows where
up.side==chocolateby applying this condition as the first argument in square brackets (see filtering rows for details). -
The second argument tests the condition
down.side=="chocolate"for each filtered row and creates a logical vector, i.e. withTRUE/FALSEvalues. Thesumfunction counts theTRUEelements of this vector (see details on handling logical values as numbers). These are then divided by the total number of filtered rows (.N).
This number is incredibly close to the desired \(\frac{2}{3}\), or 0.666.
Significance testing
We could stop here, declare victory, and it would be fine. In the interest of thoroughness, we can perform a chi-squared goodness-of-fit test to formally check if the observations deviate significantly from our expectations.
As in any significance test, there is a null hypothesis that the observations comply with our expected frequencies. If the resulting p-value is less than 0.05, then we can conclude that the observed frequencies deviate significantly from our expectation. Otherwise, we cannot reject the null hypothesis.
Note: The p-value threshold needs to be specified before performing the test and is arbitrary. The 0.05 threshold we chose is solely based on common practice. We could make it more stringent (e.g. 0.01) or more relaxed (e.g. 0.1). The p-value answers the (admittedly complicated) question: “What is the probability of these observations to come up if the null hypothesis is true?”. More information on p-values here.
# How many draws resulted in both sides chocolate
both.sides.chocolate <- biscuit.draws[up.side=="chocolate" & down.side=="chocolate", .N]
# How many draws resulted in only up-facing side chocolate
upside.only.chocolate <- biscuit.draws[up.side=="chocolate" & down.side=="icing", .N]
# Perform the chi-squared test
chisq.test(x=c(both.sides.chocolate,upside.only.chocolate),
p=c(2/3,1/3))
##
## Chi-squared test for given probabilities
##
## data: c(both.sides.chocolate, upside.only.chocolate)
## X-squared = 0.30849, df = 1, p-value = 0.5786
Code explanation
We first filter and count the rows (biscuit draws) where:
-
Both sides were chocolate (assigned to variable
both.sides.chocolate) -
Only the up-facing side was chocolate (assigned to variable
upside.only.chocolate)
The applied filters are based on combined conditions. In this case, combined with the & operator (logical AND in R), to select the rows where both subconditions are true.
The chisq.test function takes as input the observed events (x argument) and the expected frequencies (p argument), to perform the statistical test and return its output.
The resulting p-value is way higher than 0.05, which formalizes a bit more our initial conclusion: the probability in question is indeed \(\frac{2}{3}\).
Progression of frequency
So far, we’ve examined the end-point results after 2000 biscuit draws: the resulting frequency is about \(\frac{2}{3}\), which is perfectly sufficient for our question.
The benefit of data-driven analysis is, we can look at the data in any way we want. Consider the following question:
During the 2000 biscuit draws, how did the frequency progress until reaching
\(\frac{2}{3}\)?
Let’s see what the data says, on the following video:
Video 1: Progression of frequency throughout simulations. Red dashed line at \(\frac{2}{3}\).
During the first few draws the frequency fluctuates, then it sits a bit higher than \(\frac{2}{3}\), before settling at \(\frac{2}{3}\) after around 300 simulated draws. This makes sense: each biscuit draw is random individually, so the first few draws show no pattern. But the more data we gather, the more the frequency approaches the true probability.
Analytical solution
The “traditional” way to approach this problem is to lay down and count all possible outcomes to find the true probabilities. This is also called the counting method.
There are 3 biscuits, i.e. 6 up-facing sides available to draw from:
-
3 chocolate sides:
-
One side of biscuit with both sides covered in chocolate
\(\implies\)down-facing side: chocolate -
Other side of biscuit with both sides covered in chocolate
\(\implies\)down-facing side: chocolate -
Chocolate side of mixed biscuit
\(\implies\)down-facing side: icing
-
-
3 icing sides (we don’t care about these cases):
-
One side of biscuit with both sides covered in icing
\(\implies\)down-facing side: icing -
Other side of biscuit with both sides covered in icing
\(\implies\)down-facing side: icing -
Icing side of mixed biscuit
\(\implies\)down-facing side: chocolate
-
Let’s depict these outcomes in the sample space, which includes all possible outcomes of the biscuit drawing process:
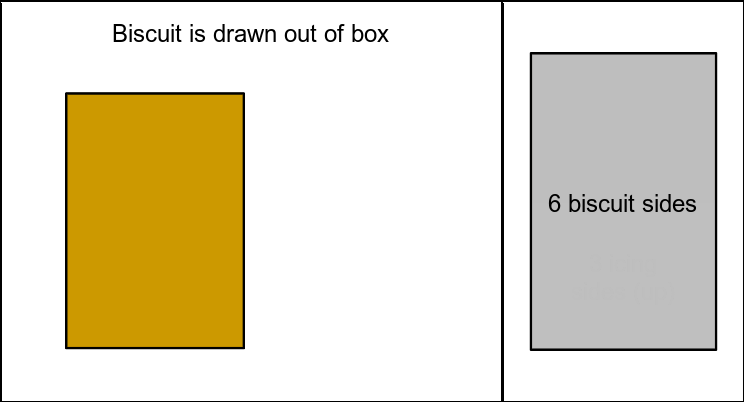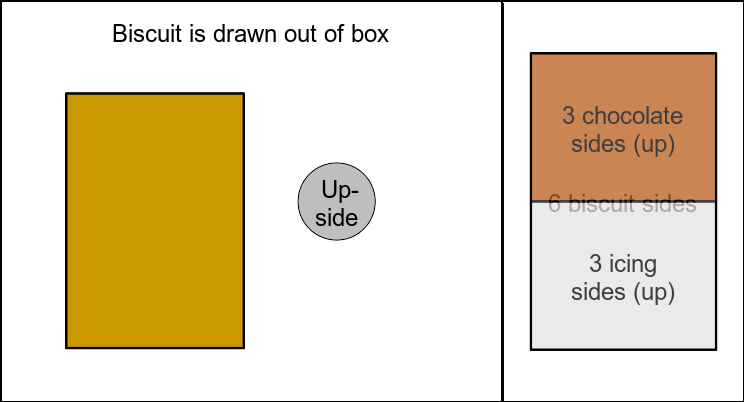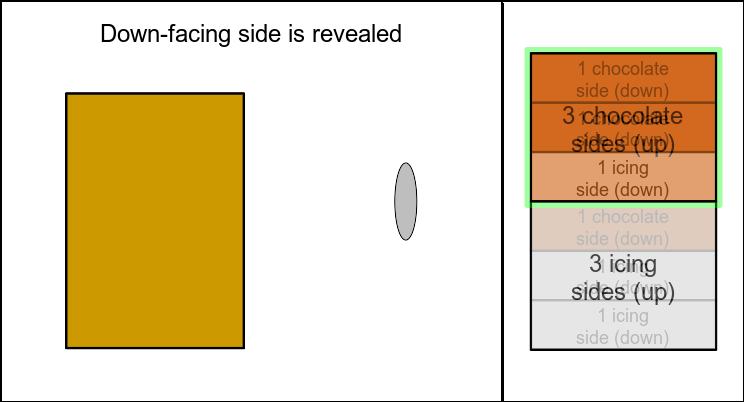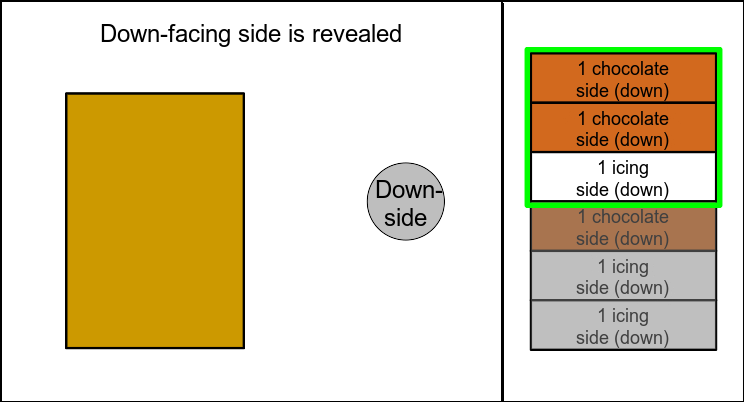
Figure 3: Left: illustration of random biscuit drawing; right: sample space including all possible outcomes of the process. Green frame on right side: considered outcomes.
It’s obvious from the outcome listing and from figure 3 that the real probability of a down-facing chocolate side after a chocolate-covered up-facing side actually is \(\frac{2}{3}\).
What’s the point
The biscuit-drawing problem gives a random process, and asks a question about probability. The analytical method is to count all possible outcomes to derive the true probabilities. On the other hand, our simulation method was to repeat the process 2000 times and look at frequencies of events as a read-out of their probabilities. The two methods arrive to the same conclusion from different angles.
By now, it’s fair to wonder: what’s the point then? Why go through the trouble to simulate hundreds or thousands of iterations and analyze data (and learn coding to do all that), when you can just use the counting method? It requires extra effort and, after all, simulations only give approximations of the true probabilities.
The analytical method is deductive. It relies on intuition to consider all outcomes of the random process and gives definitive answers. It’s a top-down approach to the answer. On the contrary, our simulation method is inductive. It is agnostic to the possible outcomes of the random process and only requires its accurate formulation, with the result emerging as a pattern from performing it. It’s a bottom-up approach.
| Analytical method | Simulation method | |
|---|---|---|
| Reasoning: | Deductive | Inductive |
| Requires: | Understanding of process and outcomes | Understanding of process, multiple iterations |
| Provides: | True probabilities | Close approximations |
Simulation approaches are not meant to substitute analytical ones but to complement them, adding value in (at least) the following ways:
-
As they don’t rely on intuition, they can point towards the right conclusions, even if they are counter-intuitive (as in the Monty Hall problem).
-
They can provide leads for analytical research.
-
Educational value:
-
They enable a more interactive pedagogical approach: recreating a process and analyzing tangible data allows the learner to reach the conclusions on their own.
-
They help the learner bridge the conceptual gap between probability theory and statistics.
-
Session info
## R version 4.6.0 (2026-04-24 ucrt)
## Platform: x86_64-w64-mingw32/x64
## Running under: Windows 11 x64 (build 26200)
##
## Matrix products: default
## LAPACK version 3.12.1
##
## locale:
## [1] LC_COLLATE=English_United States.utf8
## [2] LC_CTYPE=English_United States.utf8
## [3] LC_MONETARY=English_United States.utf8
## [4] LC_NUMERIC=C
## [5] LC_TIME=English_United States.utf8
##
## time zone: Europe/Stockholm
## tzcode source: internal
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] magick_2.9.1 plotrix_3.8-14 ggthemes_5.2.0
## [4] ggplot2_4.0.3 data.table_1.18.2.1 blogdown_1.23
##
## loaded via a namespace (and not attached):
## [1] gtable_0.3.6 jsonlite_2.0.0 dplyr_1.2.1 compiler_4.6.0
## [5] Rcpp_1.1.1-1.1 tidyselect_1.2.1 stringr_1.6.0 jquerylib_0.1.4
## [9] scales_1.4.0 yaml_2.3.12 fastmap_1.2.0 R6_2.6.1
## [13] generics_0.1.4 knitr_1.51 tibble_3.3.1 bookdown_0.46
## [17] bslib_0.10.0 pillar_1.11.1 RColorBrewer_1.1-3 rlang_1.2.0
## [21] cachem_1.1.0 stringi_1.8.7 xfun_0.57 sass_0.4.10
## [25] S7_0.2.2 otel_0.2.0 cli_3.6.6 withr_3.0.2
## [29] magrittr_2.0.5 digest_0.6.39 grid_4.6.0 rstudioapi_0.18.0
## [33] lifecycle_1.0.5 vctrs_0.7.3 evaluate_1.0.5 glue_1.8.1
## [37] farver_2.1.2 rmarkdown_2.31 purrr_1.2.2 tools_4.6.0
## [41] pkgconfig_2.0.3 htmltools_0.5.9