In this post, we will answer a question that we previously failed at:
What is the probability that two students in a classroom share the same birthday?
This is described as a paradox because for a classroom of realistic size, the probability is surprisingly higher than intuitively expected.
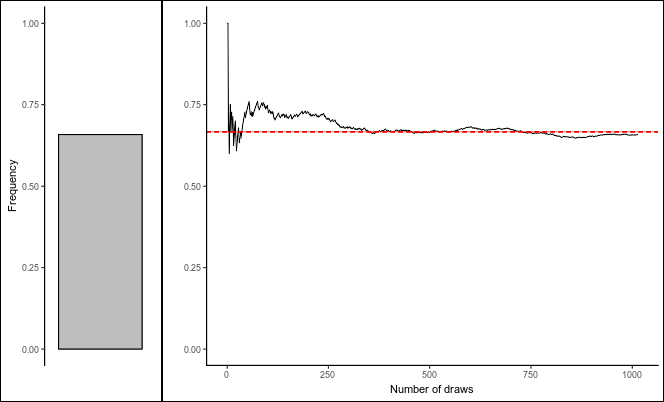
Previously, we could only solve this for very small classrooms of 2 or 3 students. The reason? Too much data.
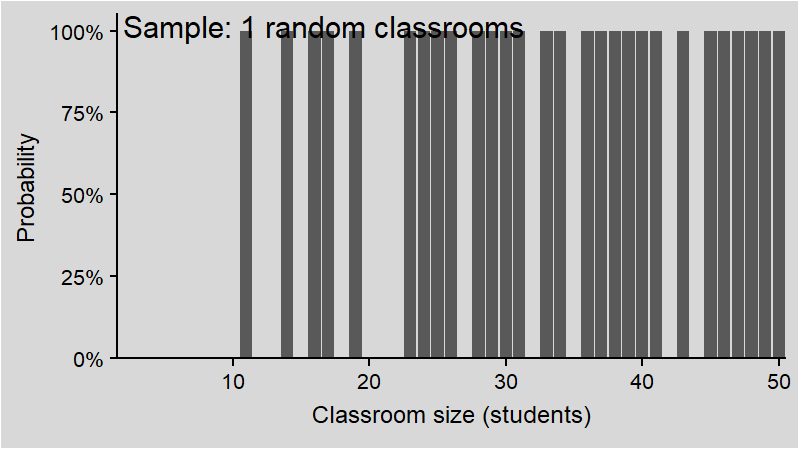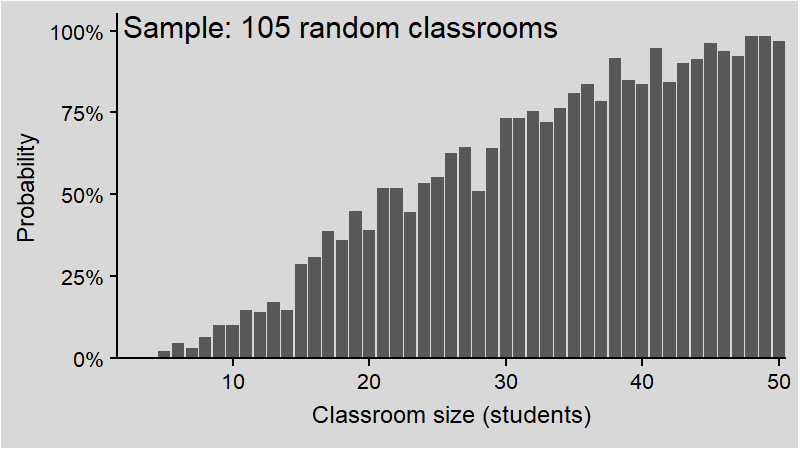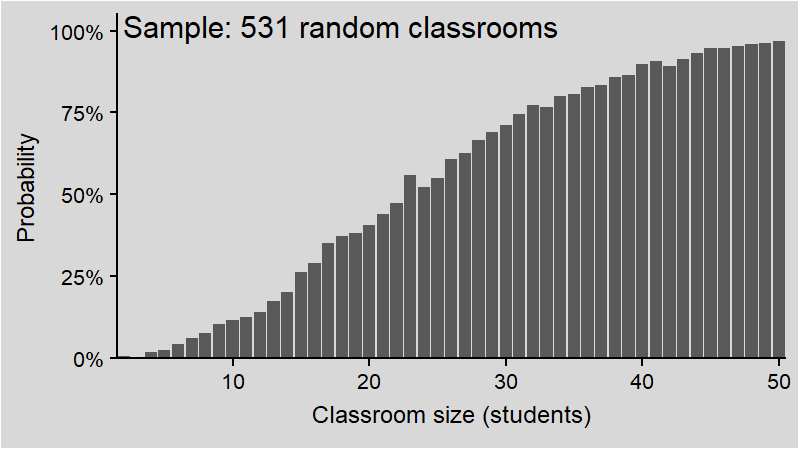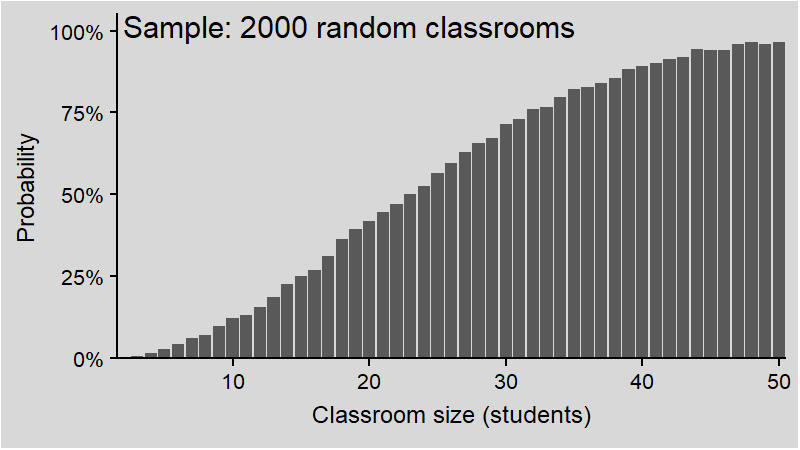
We will now get around this obstacle by the means of random sampling.
So far in this blog, we’ve tried to answer questions by creating “fake” artificial data, and finding patterns in it. That’s fun and all, but sometimes we just need data from the real world. Take for example the simple question:
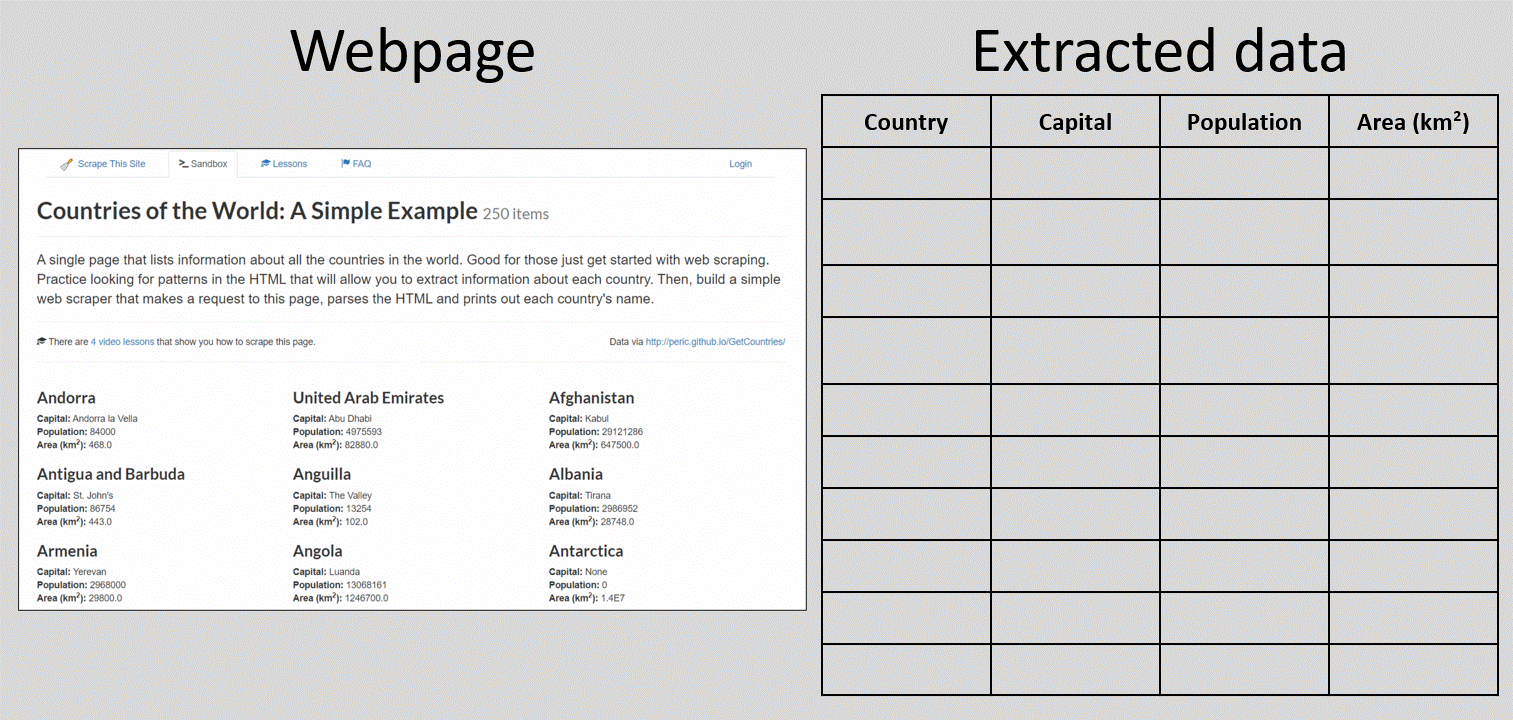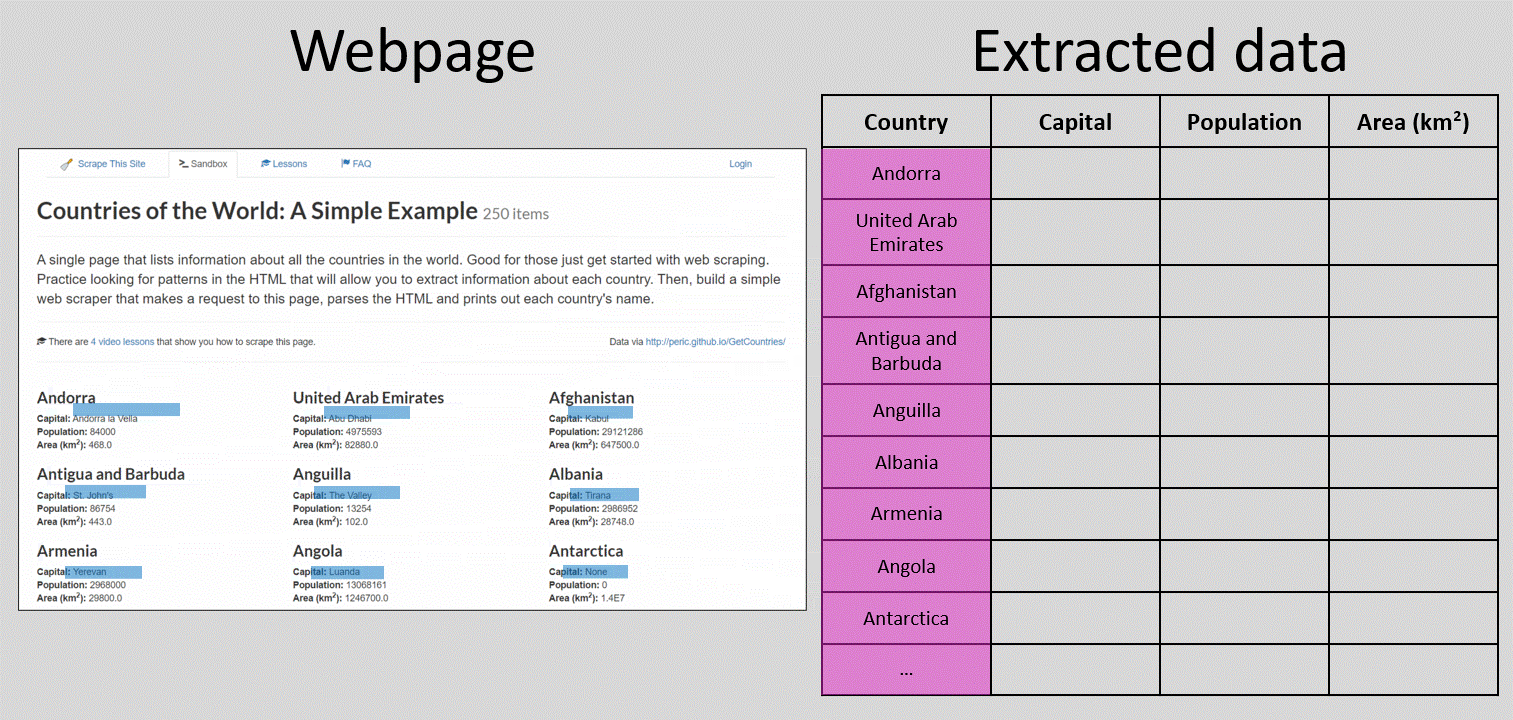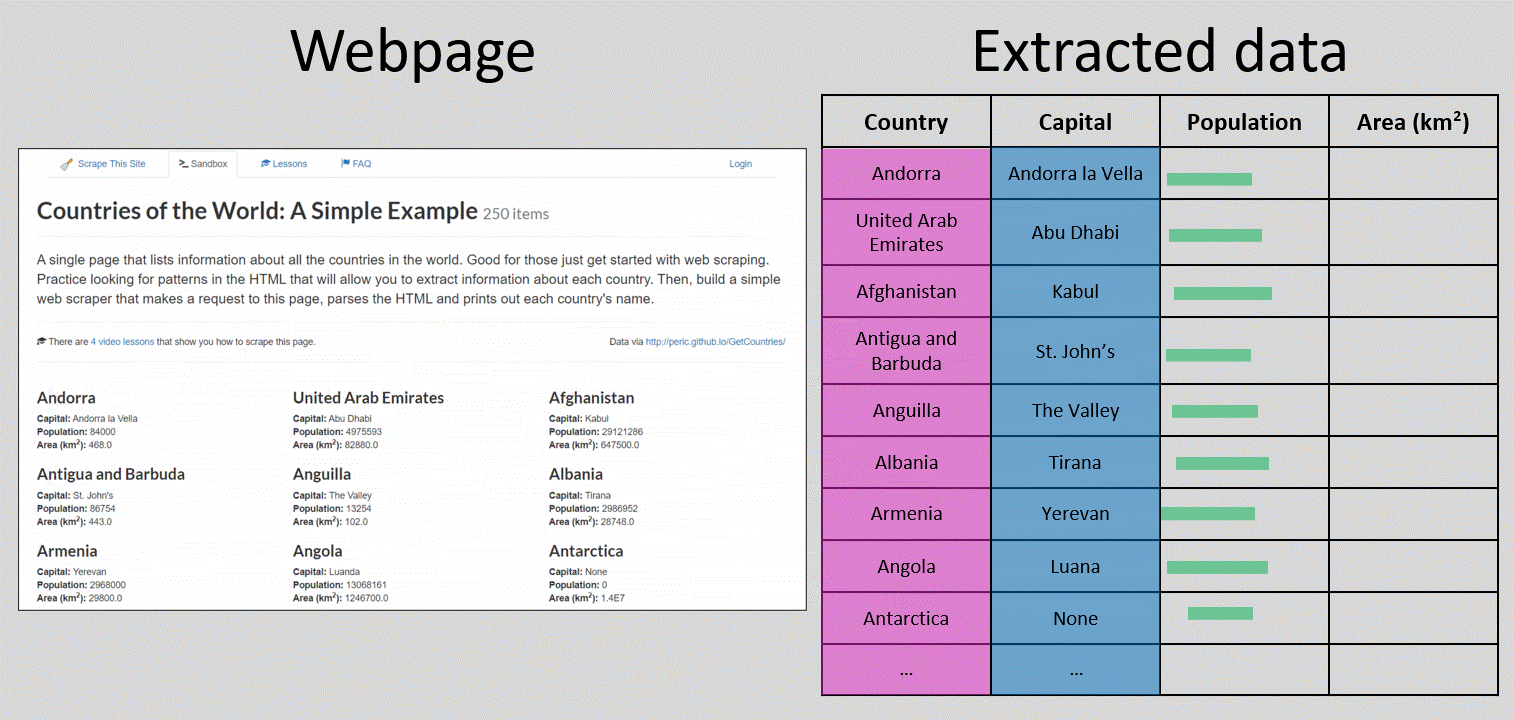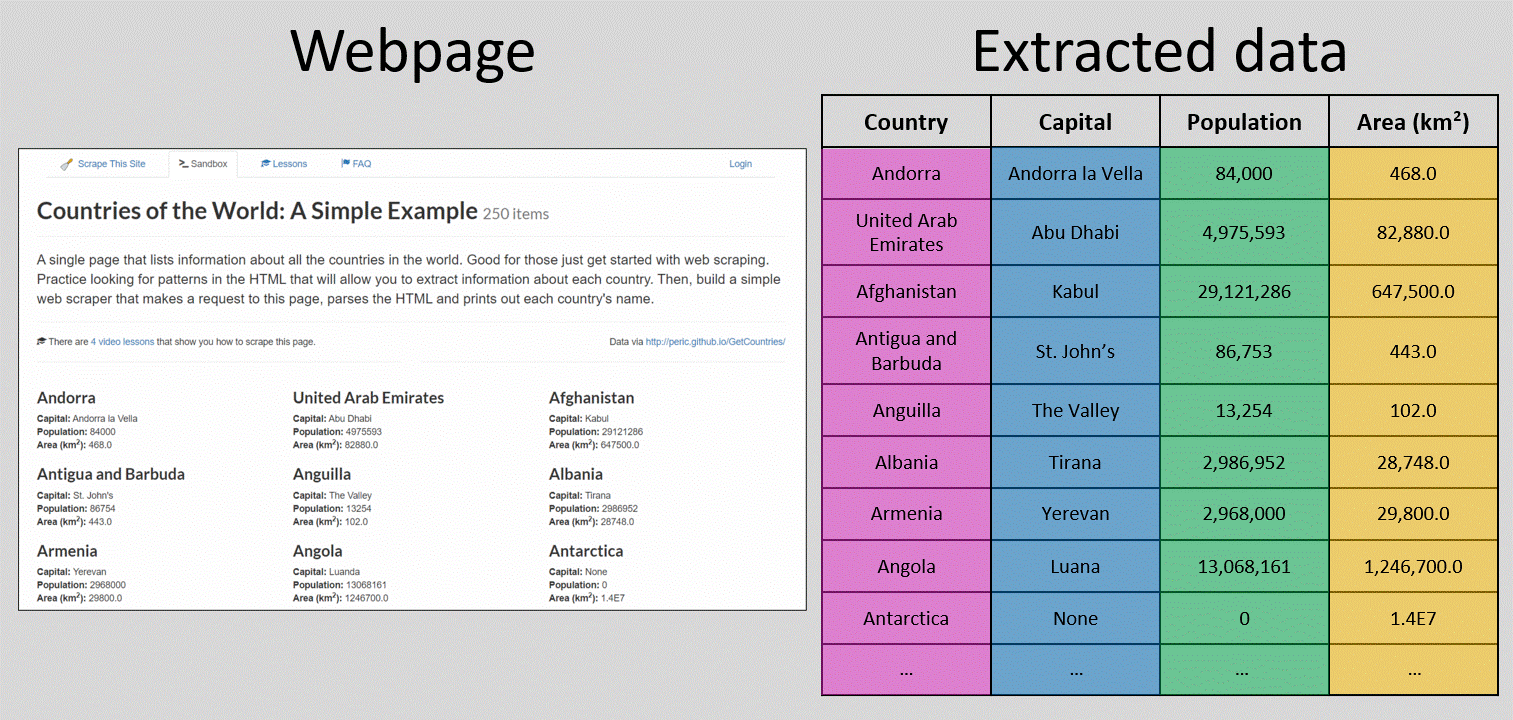
Which are the 10 most densely populated countries?
In this post we’ll focus on data collection instead of analysis. As long as the data is accessible and somewhat structured in a webpage, we’ll see how to extract it for further processing and analysis - without tedious copy-pasting but with a code-based process called web scraping.
After the “toy problem” of the previous post, I decided to take a chance at a more tangible, real-world question. Consider this one:
What is the probability that two students in a classroom share the same birthday?
Intuitively (and correctly), you might think it depends on the total number of students. But for a realistic classroom of around 20 students, the probability should be quite low - whatever “low” means. After all, how many times have you witnessed that?
I stumbled upon a probability exercise when I had just built enough confidence with R scripting, and I was looking for “toy problems” to play with. It was a simple brain teaser, barely more complicated than the well-known coin toss. I could solve it with pen and paper, but I wanted to squeeze out of it as much as I could.
My central thesis in this post is that, if we formulate our assumptions well, we can turn questions about probability into questions about data.